
文字列と文字
日本語を消す 英語を消す下記URLから引用し、日本語訳をつけてみました。
https://docs.swift.org/swift-book/documentation/the-swift-programming-language/stringsandcharacters
Store and manipulate text.
テキストを保存および操作します。
A string is a series of characters, such as "hello, world" or "albatross". Swift strings are represented by the String type. The contents of a String can be accessed in various ways, including as a collection of Character values.
文字列とは、"hello, world"や"albatross"などの一連の文字です。 Swift 文字列は String 型で表されます。 String の内容には、Character 値のコレクションとしてなど、さまざまな方法でアクセスできます。
Swift’s String and Character types provide a fast, Unicode-compliant way to work with text in your code. The syntax for string creation and manipulation is lightweight and readable, with a string literal syntax that’s similar to C. String concatenation is as simple as combining two strings with the + operator, and string mutability is managed by choosing between a constant or a variable, just like any other value in Swift. You can also use strings to insert constants, variables, literals, and expressions into longer strings, in a process known as string interpolation. This makes it easy to create custom string values for display, storage, and printing.
Swift の String タイプと Character タイプは、コード内のテキストを処理するための高速で Unicode 準拠の方法を提供します。 文字列の作成と操作の構文は軽量で読みやすく、C に似た文字列リテラル構文を使用します。文字列の連結は 2 つの文字列を + 演算子で結合するだけで簡単で、文字列の変更可能性は定数または変数のどちらかを選択することで管理されます。 Swift の他の値と同様です。 また、文字列を使用して、文字列補間と呼ばれるプロセスで、定数、変数、リテラル、および式を長い文字列に挿入することもできます。 これにより、表示、保存、印刷用のカスタム文字列値を簡単に作成できます。
Despite this simplicity of syntax, Swift’s String type is a fast, modern string implementation. Every string is composed of encoding-independent Unicode characters, and provides support for accessing those characters in various Unicode representations.
この構文の単純さにもかかわらず、Swift の String 型は高速で最新の文字列実装です。 すべての文字列はエンコーディングに依存しない Unicode 文字で構成され、さまざまな Unicode 表現でのそれらの文字へのアクセスをサポートします。
Note
注釈
Swift’s String type is bridged with Foundation’s NSString class. Foundation also extends String to expose methods defined by NSString. This means, if you import Foundation, you can access those NSString methods on String without casting.
Swift の String 型は Foundation の NSString クラスとブリッジされています。 Foundation は、NSString で定義されたメソッドを公開するために String も拡張します。 つまり、Foundation をインポートすると、キャストせずに String の NSString メソッドにアクセスできるようになります。
For more information about using String with Foundation and Cocoa, see Bridging Between String and NSString(Link:developer.apple.com).
Foundation および Cocoa で String を使用する方法の詳細については、Bridging Between String and NSString(Link:developer.apple.com)(英語)を参照してください。
String Literals
文字列リテラル
You can include predefined String values within your code as string literals. A string literal is a sequence of characters surrounded by double quotation marks (").
コード内に事前定義されたString値を文字列リテラルとして含めることができます。 文字列リテラルは、二重引用符 (“) で囲まれた一連の文字です。
Use a string literal as an initial value for a constant or variable:
文字列リテラルを定数または変数の初期値として使用します。
let someString = "Some string literal value"
Note that Swift infers a type of String for the someString constant because it’s initialized with a string literal value.
Swift は、someString 定数が文字列リテラル値で初期化されているため、String の型を推測することに注意してください。
Multiline String Literals
複数行の文字列リテラル
If you need a string that spans several lines, use a multiline string literal — a sequence of characters surrounded by three double quotation marks:
複数行にわたる文字列が必要な場合は、複数行の文字列リテラル (3 つの二重引用符で囲まれた一連の文字) を使用します。
let quotation = """
The White Rabbit put on his spectacles. "Where shall I begin,
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on
till you come to the end; then stop."
"""
A multiline string literal includes all of the lines between its opening and closing quotation marks. The string begins on the first line after the opening quotation marks (""") and ends on the line before the closing quotation marks, which means that neither of the strings below start or end with a line break:
複数行の文字列リテラルには、開始引用符と終了引用符の間にあるすべての行が含まれます。 文字列は、開始引用符 (""") の後の最初の行で始まり、終了引用符の前の行で終了します。つまり、以下の文字列はどちらも改行で開始または終了しません。
let singleLineString = "These are the same."
let multilineString = """
These are the same.
"""
When your source code includes a line break inside of a multiline string literal, that line break also appears in the string’s value. If you want to use line breaks to make your source code easier to read, but you don’t want the line breaks to be part of the string’s value, write a backslash (\) at the end of those lines:
ソース コードに複数行の文字列リテラル内に改行が含まれている場合、その改行は文字列の値にも表示されます。 ソース コードを読みやすくするために改行を使用したいが、改行を文字列値の一部にしたくない場合は、それらの行の末尾にバックスラッシュ (\) を記述します。
let softWrappedQuotation = """
The White Rabbit put on his spectacles. "Where shall I begin, \
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on \
till you come to the end; then stop."
"""
To make a multiline string literal that begins or ends with a line feed, write a blank line as the first or last line. For example:
改行で始まるか終わる複数行の文字列リテラルを作成するには、最初または最後の行に空行を記述します。 例えば:
let lineBreaks = """
This string starts with a line break.
It also ends with a line break.
"""
A multiline string can be indented to match the surrounding code. The whitespace before the closing quotation marks (""") tells Swift what whitespace to ignore before all of the other lines. However, if you write whitespace at the beginning of a line in addition to what’s before the closing quotation marks, that whitespace is included.
複数行の文字列は周囲のコードに合わせてインデントできます。 終了引用符(""")の前の空白は、他のすべての行の前にどの空白を無視するかを Swift に指示します。ただし、終了引用符の前に加えて行の先頭にも空白を書いた場合、その空白は 含まれています。

In the example above, even though the entire multiline string literal is indented, the first and last lines in the string don’t begin with any whitespace. The middle line has more indentation than the closing quotation marks, so it starts with that extra four-space indentation.
上の例では、複数行の文字列リテラル全体がインデントされていますが、文字列の最初と最後の行は空白で始まっていません。 中央の行は閉じ引用符よりもインデントが多いため、余分な 4 スペースのインデントで始まります。
Special Characters in String Literals
文字列リテラル内の特殊文字
String literals can include the following special characters:
文字列リテラルには次の特殊文字を含めることができます。
- The escaped special characters
\0(null character),\\(backslash),\t(horizontal tab),\n(line feed),\r(carriage return),\"(double quotation mark) and\'(single quotation mark) - エスケープされた特殊文字、
\0(ヌル文字)、\\(バックスラッシュ)、\t(水平タブ)、\n(ラインフィード)、\r(キャリッジリターン)、\"(二重引用符)、\'(一重引用符) クォーテーションマーク) - An arbitrary Unicode scalar value, written as
\u{n}, where n is a 1–8 digit hexadecimal number (Unicode is discussed in Unicode below) \u{n}と書かれた任意の Unicode スカラー値。n は 1 ~ 8 桁の 16 進数です(Unicode については、以下の Unicode で説明します)。
The code below shows four examples of these special characters. The wiseWords constant contains two escaped double quotation marks. The dollarSign, blackHeart, and sparklingHeart constants demonstrate the Unicode scalar format:
以下のコードは、これらの特殊文字の 4 つの例を示しています。 wiseWords 定数には、エスケープされた二重引用符が 2 つ含まれています。 dollrSign、blackHeart、sparklingHeart の定数は、Unicode スカラー形式を示します。
let wiseWords = "\"Imagination is more important than knowledge\" - Einstein"
// "Imagination is more important than knowledge" - Einstein
let dollarSign = "\u{24}" // $, Unicode scalar U+0024
let blackHeart = "\u{2665}" // ♥, Unicode scalar U+2665
let sparklingHeart = "\u{1F496}" // 💖, Unicode scalar U+1F496
Because multiline string literals use three double quotation marks instead of just one, you can include a double quotation mark (") inside of a multiline string literal without escaping it. To include the text """ in a multiline string, escape at least one of the quotation marks. For example:
複数行の文字列リテラルでは二重引用符が 1 つだけではなく 3 つ使用されるため、複数行の文字列リテラル内に二重引用符 (") をエスケープせずに含めることができます。複数行の文字列にテキスト"""を含めるには、少なくとも 1 つをエスケープします。 引用符の部分。 例えば:
let threeDoubleQuotationMarks = """
Escaping the first quotation mark \"""
Escaping all three quotation marks \"\"\"
"""
Extended String Delimiters
拡張文字列区切り文字
You can place a string literal within extended delimiters to include special characters in a string without invoking their effect. You place your string within quotation marks (") and surround that with number signs (#). For example, printing the string literal #"Line 1\nLine 2"# prints the line feed escape sequence (\n) rather than printing the string across two lines.
文字列リテラルを拡張区切り文字内に配置すると、その効果を呼び出すことなく文字列に特殊文字を含めることができます。 文字列を引用符 (") で囲み、シャープ記号 (#) で囲みます。たとえば、文字列リテラル #"Line 1\nLine 2"# を出力すると、 2 行にわたる文字列を出力するのではなく、改行エスケープ シーケンス (\n) が出力されます。
If you need the special effects of a character in a string literal, match the number of number signs within the string following the escape character (\). For example, if your string is #"Line 1\nLine 2"# and you want to break the line, you can use #"Line 1\#nLine 2"# instead. Similarly, ###"Line1\###nLine2"### also breaks the line.
文字列リテラル内の文字の特殊効果が必要な場合は、エスケープ文字 () に続く文字列内のシャープ記号の数を一致させます。 たとえば、文字列が #"Line 1\nLine 2"# で、改行したい場合は、代わりに #"Line 1#nLine 2"# を使用できます。 同様に、###"Line1###nLine2"### も改行します。
String literals created using extended delimiters can also be multiline string literals. You can use extended delimiters to include the text """ in a multiline string, overriding the default behavior that ends the literal. For example:
拡張区切り文字を使用して作成された文字列リテラルは、複数行の文字列リテラルにすることもできます。 拡張区切り文字を使用すると、リテラルを終了するデフォルトの動作をオーバーライドして、テキスト"""を複数行の文字列に含めることができます。次に例を示します。
let threeMoreDoubleQuotationMarks = #"""
Here are three more double quotes: """
"""#
Initializing an Empty String
空の文字列の初期化
To create an empty String value as the starting point for building a longer string, either assign an empty string literal to a variable or initialize a new String instance with initializer syntax:
長い文字列を構築するための開始点として空のString値を作成するには、空の文字列リテラルを変数に割り当てるか、イニシャライザ構文を使用して新しいStringインスタンスを初期化します。
var emptyString = "" // empty string literal
var anotherEmptyString = String() // initializer syntax
// these two strings are both empty, and are equivalent to each other
Find out whether a String value is empty by checking its Boolean isEmpty property:
Boolean isEmpty プロパティをチェックして、String 値が空かどうかを確認します。
if emptyString.isEmpty {
print("Nothing to see here")
}
// Prints "Nothing to see here"
String Mutability
文字列の可変性
You indicate whether a particular String can be modified (or mutated) by assigning it to a variable (in which case it can be modified), or to a constant (in which case it can’t be modified):
特定のStringを変数(変更できる場合)または定数(変更できない場合)に割り当てることによって、変更(または変更)できるかどうかを示します。
var variableString = "Horse"
variableString += " and carriage"
// variableString is now "Horse and carriage"
let constantString = "Highlander"
constantString += " and another Highlander"
// this reports a compile-time error - a constant string cannot be modified
Note
注釈
This approach is different from string mutation in Objective-C and Cocoa, where you choose between two classes (NSString and NSMutableString) to indicate whether a string can be mutated.
このアプローチは、文字列を変更できるかどうかを示すために 2 つのクラス (NSString と NSMutableString) のどちらかを選択する Objective-C や Cocoa の文字列変更とは異なります。
Strings Are Value Types
Stringは値の型です
Swift’s String type is a value type. If you create a new String value, that String value is copied when it’s passed to a function or method, or when it’s assigned to a constant or variable. In each case, a new copy of the existing String value is created, and the new copy is passed or assigned, not the original version. Value types are described in Structures and Enumerations Are Value Types.
Swift の String 型は値の型です。 新しいString値を作成した場合、そのString値は関数やメソッドに渡されるとき、または定数や変数に割り当てられるときにコピーされます。 いずれの場合も、既存のString値の新しいコピーが作成され、元のバージョンではなく、新しいコピーが渡されるか割り当てられます。 値のタイプについては、「構造体と列挙は値のタイプ」で説明されています。
Swift’s copy-by-default String behavior ensures that when a function or method passes you a String value, it’s clear that you own that exact String value, regardless of where it came from. You can be confident that the string you are passed won’t be modified unless you modify it yourself.
Swift のデフォルトでコピーされる String 動作により、関数またはメソッドが String 値を渡すときに、その String 値がどこから来たのかに関係なく、その正確な String 値を所有していることが明確になります。 渡された文字列は、自分で変更しない限り変更されないことを確信できます。
Behind the scenes, Swift’s compiler optimizes string usage so that actual copying takes place only when absolutely necessary. This means you always get great performance when working with strings as value types.
Swift のコンパイラは舞台裏で文字列の使用を最適化し、実際のコピーが絶対に必要な場合にのみ行われるようにします。 これは、文字列を値の型として操作するときに常に優れたパフォーマンスが得られることを意味します。
Working with Characters
キャラクターの操作
You can access the individual Character values for a String by iterating over the string with a for–in loop:
for-in ループを使用してStringを反復処理することで、文字列の個々のCharacter値にアクセスできます。
for character in "Dog!🐶" {
print(character)
}
// D
// o
// g
// !
// 🐶
The for–in loop is described in For-In Loops.
for-in ループについては、For-In ループで説明されています。
Alternatively, you can create a stand-alone Character constant or variable from a single-character string literal by providing a Character type annotation:
あるいは、Character タイプのアノテーションを指定して、単一文字の文字列リテラルからスタンドアロンの Character 定数または変数を作成することもできます。
let exclamationMark: Character = "!"
String values can be constructed by passing an array of Character values as an argument to its initializer:
String値は、Character値の配列を引数として初期化子に渡すことで構築できます。
let catCharacters: [Character] = ["C", "a", "t", "!", "🐱"]
let catString = String(catCharacters)
print(catString)
// Prints "Cat!🐱"
Concatenating Strings and Characters
文字列と文字の連結
String values can be added together (or concatenated) with the addition operator (+) to create a new String value:
String値は、加算演算子 (+) を使用して追加 (または連結) して、新しいString値を作成できます。
let string1 = "hello"
let string2 = " there"
var welcome = string1 + string2
// welcome now equals "hello there"
You can also append a String value to an existing String variable with the addition assignment operator (+=):
追加代入演算子 (+=) を使用して、既存のString変数にString値を追加することもできます。
var instruction = "look over"
instruction += string2
// instruction now equals "look over there"
You can append a Character value to a String variable with the String type’s append() method:
String 型の append() メソッドを使用して、Character 値を String 変数に追加できます。
let exclamationMark: Character = "!"
welcome.append(exclamationMark)
// welcome now equals "hello there!"
Note
注釈
You can’t append a String or Character to an existing Character variable, because a Character value must contain a single character only.
Character 値には 1 つの文字のみを含める必要があるため、既存の Character 変数に String または Character を追加することはできません。
If you’re using multiline string literals to build up the lines of a longer string, you want every line in the string to end with a line break, including the last line. For example:
複数行の文字列リテラルを使用して長い文字列の行を構築している場合は、最後の行を含め、文字列内のすべての行を改行で終了する必要があります。 例えば:
let badStart = """
one
two
"""
let end = """
three
"""
print(badStart + end)
// Prints two lines:
// one
// twothree
let goodStart = """
one
two
"""
print(goodStart + end)
// Prints three lines:
// one
// two
// three
In the code above, concatenating badStart with end produces a two-line string, which isn’t the desired result. Because the last line of badStart doesn’t end with a line break, that line gets combined with the first line of end. In contrast, both lines of goodStart end with a line break, so when it’s combined with end the result has three lines, as expected.
上記のコードでは、badStart と end を連結すると 2 行の文字列が生成されますが、これは望ましい結果ではありません。 badStart の最後の行は改行で終わっていないため、その行は end の最初の行と結合されます。 対照的に、goodStart の両方の行は改行で終わるため、end と組み合わせると、予想どおり 3 行の結果になります。
String Interpolation
文字列補間
String interpolation is a way to construct a new String value from a mix of constants, variables, literals, and expressions by including their values inside a string literal. You can use string interpolation in both single-line and multiline string literals. Each item that you insert into the string literal is wrapped in a pair of parentheses, prefixed by a backslash (\):
文字列補間は、定数、変数、リテラル、式の値を文字列リテラル内に含めることで、これらの値を組み合わせて新しいString値を構築する方法です。 文字列補間は、単一行文字列リテラルと複数行文字列リテラルの両方で使用できます。 文字列リテラルに挿入する各項目は、前にバックスラッシュ (\) が付けられた一対のかっこで囲まれます。
let multiplier = 3
let message = "\(multiplier) times 2.5 is \(Double(multiplier) * 2.5)"
// message is "3 times 2.5 is 7.5"
In the example above, the value of multiplier is inserted into a string literal as \(multiplier). This placeholder is replaced with the actual value of multiplier when the string interpolation is evaluated to create an actual string.
上の例では、multiplier の値が \(multiplier) として文字列リテラルに挿入されます。 このプレースホルダは、文字列補間が評価されて実際の文字列が作成されるときに、multiplierの実際の値に置き換えられます。
The value of multiplier is also part of a larger expression later in the string. This expression calculates the value of Double(multiplier) * 2.5 and inserts the result (7.5) into the string. In this case, the expression is written as \(Double(multiplier) * 2.5) when it’s included inside the string literal.
multiplier の値は、文字列の後半にあるより大きな式の一部でもあります。 この式は、Double(multiplier) * 2.5 の値を計算し、結果 (7.5) を文字列に挿入します。 この場合、式が文字列リテラル内に含まれる場合、式は \(Double(multiplier) * 2.5) として記述されます。
You can use extended string delimiters to create strings containing characters that would otherwise be treated as a string interpolation. For example:
拡張文字列区切り文字を使用すると、文字列補間として扱われる文字を含む文字列を作成できます。 例えば:
print(#"Write an interpolated string in Swift using \(multiplier)."#)
// Prints "Write an interpolated string in Swift using \(multiplier)."
To use string interpolation inside a string that uses extended delimiters, match the number of number signs after the backslash to the number of number signs at the beginning and end of the string. For example:
拡張区切り文字を使用する文字列内で文字列補間を使用するには、バックスラッシュの後のシャープ記号の数を文字列の先頭と末尾のシャープ記号の数と一致させます。 例えば:
print(#"6 times 7 is \#(6 * 7)."#)
// Prints "6 times 7 is 42."
Note
注釈
The expressions you write inside parentheses within an interpolated string can’t contain an unescaped backslash (\), a carriage return, or a line feed. However, they can contain other string literals.
補間文字列内の括弧内に記述する式には、エスケープされていないバックスラッシュ (\)、キャリッジ リターン、またはライン フィードを含めることはできません。 ただし、他の文字列リテラルを含めることもできます。
Unicode
ユニコード
Unicode is an international standard for encoding, representing, and processing text in different writing systems. It enables you to represent almost any character from any language in a standardized form, and to read and write those characters to and from an external source such as a text file or web page. Swift’s String and Character types are fully Unicode-compliant, as described in this section.
Unicode は、さまざまな書記体系でテキストをエンコード、表現、処理するための国際標準です。 これにより、あらゆる言語のほぼすべての文字を標準化された形式で表現し、テキスト ファイルや Web ページなどの外部ソースとの間でそれらの文字を読み書きできるようになります。 このセクションで説明するように、Swift の String タイプと Character タイプは完全に Unicode に準拠しています。
Unicode Scalar Values
Unicode スカラー値
Behind the scenes, Swift’s native String type is built from Unicode scalar values. A Unicode scalar value is a unique 21-bit number for a character or modifier, such as U+0061 for LATIN SMALL LETTER A ("a"), or U+1F425 for FRONT-FACING BABY CHICK ("🐥").
バックグラウンドでは、Swift のネイティブ String 型は Unicode scalar valuesから構築されます。 Unicode スカラー値は、文字または修飾子に固有の 21 ビットの数値です。たとえば、ラテン小文字 A ("a") の場合は U+0061、正面向きの赤ちゃんのひよこ ("🐥") の場合は U+1F425 です。
Note that not all 21-bit Unicode scalar values are assigned to a character — some scalars are reserved for future assignment or for use in UTF-16 encoding. Scalar values that have been assigned to a character typically also have a name, such as LATIN SMALL LETTER A and FRONT-FACING BABY CHICK in the examples above.
すべての 21 ビット Unicode スカラー値が文字に割り当てられるわけではないことに注意してください。一部のスカラーは、将来の割り当てまたは UTF-16 エンコードでの使用のために予約されています。 文字に割り当てられたスカラー値には、通常、上記の例の「LATIN SMALL LETTER A」や「FRONT-FACING BABY CHICK」などの名前もあります。
Extended Grapheme Clusters
拡張書記素クラスター
Every instance of Swift’s Character type represents a single extended grapheme cluster. An extended grapheme cluster is a sequence of one or more Unicode scalars that (when combined) produce a single human-readable character.
Swift の Character タイプのすべてのインスタンスは、単一の拡張書記素クラスターを表します。 拡張書記素クラスターは、(結合すると) 単一の人間が読める文字を生成する 1 つ以上の Unicode スカラーのシーケンスです。
Here’s an example. The letter é can be represented as the single Unicode scalar é (LATIN SMALL LETTER E WITH ACUTE, or U+00E9). However, the same letter can also be represented as a pair of scalars — a standard letter e (LATIN SMALL LETTER E, or U+0065), followed by the COMBINING ACUTE ACCENT scalar (U+0301). The COMBINING ACUTE ACCENT scalar is graphically applied to the scalar that precedes it, turning an e into an é when it’s rendered by a Unicode-aware text-rendering system.
以下に例を示します。 文字 é は、単一の Unicode スカラー é (LATIN SMALL LETTER E WITH ACUTE、または U+00E9) として表すことができます。 ただし、同じ文字をスカラーのペアとして表すこともできます。標準的な文字 e (LATIN SMALL LETTER E、または U+0065) の後に COBINING ACUTE ACCENT スカラー (U+0301) が続きます。 COBINING ACUTE ACCENT スカラーは、その前のスカラーにグラフィカルに適用され、Unicode 対応のテキスト レンダリング システムによってレンダリングされるときに e が é に変わります。
In both cases, the letter é is represented as a single Swift Character value that represents an extended grapheme cluster. In the first case, the cluster contains a single scalar; in the second case, it’s a cluster of two scalars:
どちらの場合も、文字「é」は拡張書記素クラスターを表す単一の Swift Character 値として表されます。 最初のケースでは、クラスターには単一のスカラーが含まれています。 2 番目のケースでは、2 つのスカラーのクラスターです。
let eAcute: Character = "\u{E9}" // é
let combinedEAcute: Character = "\u{65}\u{301}" // e followed by ́
// eAcute is é, combinedEAcute is é
Extended grapheme clusters are a flexible way to represent many complex script characters as a single Character value. For example, Hangul syllables from the Korean alphabet can be represented as either a precomposed or decomposed sequence. Both of these representations qualify as a single Character value in Swift:
拡張書記素クラスタは、多くの複雑なスクリプト文字を単一の文字値として表現する柔軟な方法です。 たとえば、韓国語のアルファベットのハングル音節は、事前に合成されたシーケンスまたは分解されたシーケンスとして表現できます。 これらの表現は両方とも、Swift では単一の Character 値として認められます。
let precomposed: Character = "\u{D55C}" // 한
let decomposed: Character = "\u{1112}\u{1161}\u{11AB}" // ᄒ, ᅡ, ᆫ
// precomposed is 한, decomposed is 한
Extended grapheme clusters enable scalars for enclosing marks (such as COMBINING ENCLOSING CIRCLE, or U+20DD) to enclose other Unicode scalars as part of a single Character value:
拡張書記素クラスタにより、マークを囲むスカラー (COMBINING ENCLOSING CIRCLE や U+20DD など) が他の Unicode スカラーを単一の Character 値の一部として囲むことが可能になります。
let enclosedEAcute: Character = "\u{E9}\u{20DD}"
// enclosedEAcute is é⃝
Unicode scalars for regional indicator symbols can be combined in pairs to make a single Character value, such as this combination of REGIONAL INDICATOR SYMBOL LETTER U (U+1F1FA) and REGIONAL INDICATOR SYMBOL LETTER S (U+1F1F8):
地域インジケーター記号の Unicode スカラーをペアで組み合わせて、単一の文字値を作成できます。たとえば、REGIONAL INDICATOR SYMBOL LETTER U (U+1F1FA) とREGIONAL INDICATOR SYMBOL LETTER S (U+1F1F8) の組み合わせです。
let regionalIndicatorForUS: Character = "\u{1F1FA}\u{1F1F8}"
// regionalIndicatorForUS is 🇺🇸
Counting Characters
文字数を数える
To retrieve a count of the Character values in a string, use the count property of the string:
文字列内のCharacter値の数を取得するには、文字列の count プロパティを使用します。
let unusualMenagerie = "Koala 🐨, Snail 🐌, Penguin 🐧, Dromedary 🐪"
print("unusualMenagerie has \(unusualMenagerie.count) characters")
// Prints "unusualMenagerie has 40 characters"
Note that Swift’s use of extended grapheme clusters for Character values means that string concatenation and modification may not always affect a string’s character count.
Swift では文字値に拡張書記素クラスタを使用しているため、文字列の連結と変更が文字列の文字数に必ずしも影響するとは限らないことに注意してください。
For example, if you initialize a new string with the four-character word cafe, and then append a COMBINING ACUTE ACCENT (U+0301) to the end of the string, the resulting string will still have a character count of 4, with a fourth character of é, not e:
たとえば、4 文字の単語「cafe」で新しい文字列を初期化し、文字列の末尾に COBINING ACUTE ACCENT (U+0301) を追加した場合、結果の文字列の文字数は 4 のままになります。 e ではなく、é の 4 番目の文字:
var word = "cafe"
print("the number of characters in \(word) is \(word.count)")
// Prints "the number of characters in cafe is 4"
word += "\u{301}" // COMBINING ACUTE ACCENT, U+0301
print("the number of characters in \(word) is \(word.count)")
// Prints "the number of characters in café is 4"
Note
注釈
Extended grapheme clusters can be composed of multiple Unicode scalars. This means that different characters — and different representations of the same character — can require different amounts of memory to store. Because of this, characters in Swift don’t each take up the same amount of memory within a string’s representation. As a result, the number of characters in a string can’t be calculated without iterating through the string to determine its extended grapheme cluster boundaries. If you are working with particularly long string values, be aware that the count property must iterate over the Unicode scalars in the entire string in order to determine the characters for that string.
拡張書記素クラスターは、複数の Unicode スカラーで構成できます。 これは、異なる文字、および同じ文字の異なる表現では、保存するために必要なメモリ量が異なる可能性があることを意味します。 このため、Swift の文字は、文字列表現内でそれぞれ同じ量のメモリを占有するわけではありません。 その結果、文字列内の文字数は、文字列を反復処理して拡張書記素クラスターの境界を決定することなしに計算することはできません。 特に長い文字列値を扱う場合は、その文字列の文字を決定するために、count プロパティで文字列全体の Unicode スカラーを反復処理する必要があることに注意してください。
The count of the characters returned by the count property isn’t always the same as the length property of an NSString that contains the same characters. The length of an NSString is based on the number of 16-bit code units within the string’s UTF-16 representation and not the number of Unicode extended grapheme clusters within the string.
count プロパティによって返される文字数は、同じ文字を含む NSString のlengthプロパティと必ずしも同じではありません。 NSString の長さは、文字列内の Unicode 拡張書記素クラスタの数ではなく、文字列の UTF-16 表現内の 16 ビット コード単位の数に基づいています。
Accessing and Modifying a String
文字列へのアクセスと変更
You access and modify a string through its methods and properties, or by using subscript syntax.
文字列にアクセスして変更するには、そのメソッドとプロパティを使用するか、添え字構文を使用します。
String Indices
文字列インデックス
Each String value has an associated index type, String.Index, which corresponds to the position of each Character in the string.
各String 値には、文字列内の各Characterの位置に対応するindex type String.Index が関連付けられています。
As mentioned above, different characters can require different amounts of memory to store, so in order to determine which Character is at a particular position, you must iterate over each Unicode scalar from the start or end of that String. For this reason, Swift strings can’t be indexed by integer values.
上で述べたように、文字が異なれば、保存に必要なメモリ量も異なる場合があるため、どのCharacterが特定の位置にあるかを判断するには、そのStringの先頭または末尾から各 Unicode スカラーを反復処理する必要があります。 このため、Swift 文字列は整数値でインデックスを付けることができません。
Use the startIndex property to access the position of the first Character of a String. The endIndex property is the position after the last character in a String. As a result, the endIndex property isn’t a valid argument to a string’s subscript. If a String is empty, startIndex and endIndex are equal.
startIndex プロパティを使用して、Stringの最初のCharacter の位置にアクセスします。 endIndex プロパティは、Stringの最後の文字の後の位置です。 結果として、endIndex プロパティは文字列の添字に対する有効な引数ではありません。 String が空の場合、startIndex と endIndex は等しくなります。
You access the indices before and after a given index using the index(before:) and index(after:) methods of String. To access an index farther away from the given index, you can use the index(_:offsetBy:) method instead of calling one of these methods multiple times.
String の Index(before:) メソッドと Index(after:) メソッドを使用して、特定のインデックスの前後のインデックスにアクセスします。 指定されたインデックスから遠く離れたインデックスにアクセスするには、これらのメソッドのいずれかを複数回呼び出す代わりに、index(_:offsetBy:) メソッドを使用できます。
You can use subscript syntax to access the Character at a particular String index.
添え字構文を使用して、特定のStringインデックスの文字にアクセスできます。
let greeting = "Guten Tag!"
greeting[greeting.startIndex]
// G
greeting[greeting.index(before: greeting.endIndex)]
// !
greeting[greeting.index(after: greeting.startIndex)]
// u
let index = greeting.index(greeting.startIndex, offsetBy: 7)
greeting[index]
// a
Attempting to access an index outside of a string’s range or a Character at an index outside of a string’s range will trigger a runtime error.
文字列の範囲外のインデックス、または文字列の範囲外のインデックスにあるCharacterにアクセスしようとすると、実行時エラーが発生します。
greeting[greeting.endIndex] // Error
greeting.index(after: greeting.endIndex) // Error
Use the indices property to access all of the indices of individual characters in a string.
文字列内の個々の文字のすべてのインデックスにアクセスするには、indices プロパティを使用します。
for index in greeting.indices {
print("\(greeting[index]) ", terminator: "")
}
// Prints "G u t e n T a g ! "
Note
注釈
You can use the startIndex and endIndex properties and the index(before:), index(after:), and index(_:offsetBy:) methods on any type that conforms to the Collection protocol. This includes String, as shown here, as well as collection types such as Array, Dictionary, and Set.
startIndex プロパティと endIndex プロパティ、および Index(before:)、index(after:)、index(_:offsetBy:) メソッドは、Collection プロトコルに準拠する任意の型で使用できます。 これには、ここに示すように String のほか、Array、Dictionary、Set などのコレクション タイプが含まれます。
Inserting and Removing
挿入と削除
To insert a single character into a string at a specified index, use the insert(_:at:) method, and to insert the contents of another string at a specified index, use the insert(contentsOf:at:) method.
指定したインデックスの文字列に単一の文字を挿入するには、insert(_:at:) メソッドを使用します。指定したインデックスに別の文字列の内容を挿入するには、insert(contentsOf:at:) メソッドを使用します。
var welcome = "hello"
welcome.insert("!", at: welcome.endIndex)
// welcome now equals "hello!"
welcome.insert(contentsOf: " there", at: welcome.index(before: welcome.endIndex))
// welcome now equals "hello there!"
To remove a single character from a string at a specified index, use the remove(at:) method, and to remove a substring at a specified range, use the removeSubrange(_:) method:
指定したインデックスにある文字列から 1 文字を削除するには、remove(at:) メソッドを使用します。指定した範囲の部分文字列を削除するには、removeSubrange(_:) メソッドを使用します。
welcome.remove(at: welcome.index(before: welcome.endIndex))
// welcome now equals "hello there"
let range = welcome.index(welcome.endIndex, offsetBy: -6)..<welcome.endIndex
welcome.removeSubrange(range)
// welcome now equals "hello"
Note
注釈
You can use the insert(_:at:), insert(contentsOf:at:), remove(at:), and removeSubrange(_:) methods on any type that conforms to the RangeReplaceableCollection protocol. This includes String, as shown here, as well as collection types such as Array, Dictionary, and Set.
RangeReplaceableCollection プロトコルに準拠する任意の型に対して、insert(:at:)、insert(contentsOf:at:)、remove(at:)、removeSubrange(:) メソッドを使用できます。 これには、ここに示すように String のほか、Array、Dictionary、Set などのコレクション タイプが含まれます。
Substrings
部分文字列
When you get a substring from a string — for example, using a subscript or a method like prefix(_:) — the result is an instance of Substring(Link:developer.apple.com), not another string. Substrings in Swift have most of the same methods as strings, which means you can work with substrings the same way you work with strings. However, unlike strings, you use substrings for only a short amount of time while performing actions on a string. When you’re ready to store the result for a longer time, you convert the substring to an instance of String. For example:
たとえば、添え字やprefix(_:) などのメソッドを使用して、文字列から部分文字列を取得すると、結果は別の文字列ではなく、Substring(Link:developer.apple.com)(英語)のインスタンスになります。 Swift の部分文字列には文字列とほとんど同じメソッドがあります。つまり、文字列を操作するのと同じ方法で部分文字列を操作できます。 ただし、文字列とは異なり、部分文字列は、文字列に対してアクションを実行するときにのみ使用します。 結果を長期間保存する準備ができたら、部分文字列を String のインスタンスに変換します。 例えば:
let greeting = "Hello, world!"
let index = greeting.firstIndex(of: ",") ?? greeting.endIndex
let beginning = greeting[..<index]
// beginning is "Hello"
// Convert the result to a String for long-term storage.
let newString = String(beginning)
Like strings, each substring has a region of memory where the characters that make up the substring are stored. The difference between strings and substrings is that, as a performance optimization, a substring can reuse part of the memory that’s used to store the original string, or part of the memory that’s used to store another substring. (Strings have a similar optimization, but if two strings share memory, they’re equal.) This performance optimization means you don’t have to pay the performance cost of copying memory until you modify either the string or substring. As mentioned above, substrings aren’t suitable for long-term storage — because they reuse the storage of the original string, the entire original string must be kept in memory as long as any of its substrings are being used.
文字列と同様に、各部分文字列には、部分文字列を構成する文字が格納されるメモリ領域があります。 文字列と部分文字列の違いは、パフォーマンスの最適化として、部分文字列は元の文字列の保存に使用されるメモリの一部、または別の部分文字列の保存に使用されるメモリの一部を再利用できることです。 (文字列にも同様の最適化がありますが、2 つの文字列がメモリを共有する場合、それらは同等になります。) このパフォーマンスの最適化は、文字列または部分文字列のいずれかを変更するまで、メモリのコピーによるパフォーマンス コストを支払う必要がないことを意味します。 上で述べたように、部分文字列は長期保存には適していません。部分文字列は元の文字列のストレージを再利用するため、部分文字列が使用されている限り、元の文字列全体をメモリ内に保持する必要があります。
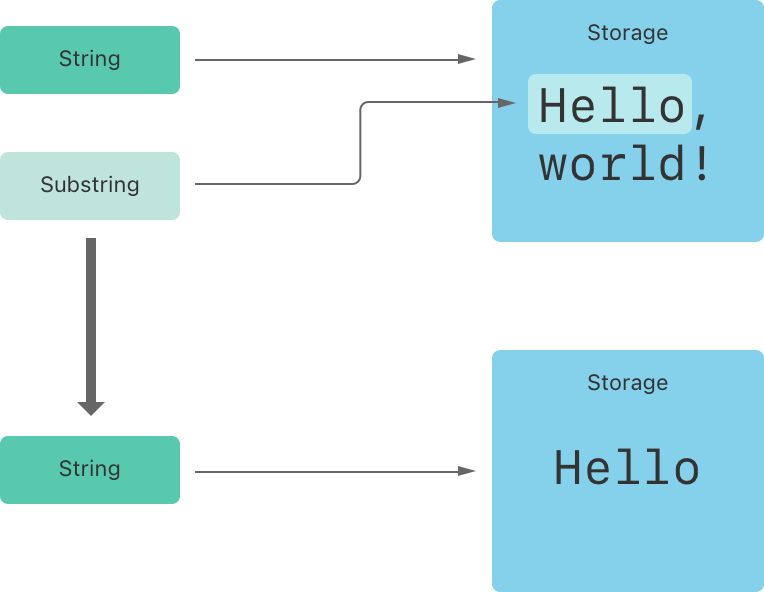
In the example above, greeting is a string, which means it has a region of memory where the characters that make up the string are stored. Because beginning is a substring of greeting, it reuses the memory that greeting uses. In contrast, newString is a string — when it’s created from the substring, it has its own storage. The figure below shows these relationships:
上の例では、greeting は文字列です。つまり、文字列を構成する文字が保存されるメモリ領域があることを意味します。beginningはgreetingの部分文字列であるため、greetingで使用されるメモリが再利用されます。 対照的に、newString は文字列です。部分文字列から作成されると、独自のストレージがあります。 以下の図は、これらの関係を示しています。
Note
注釈
Both String and Substring conform to the StringProtocol(Link:developer.apple.com) protocol, which means it’s often convenient for string-manipulation functions to accept a StringProtocol value. You can call such functions with either a String or Substring value.
String と Substring はどちらも StringProtocol(Link:developer.apple.com)(英語)プロトコルに準拠しています。つまり、文字列操作関数が StringProtocol 値を受け入れると便利なことがよくあります。 このような関数は、String またはSubstring値を使用して呼び出すことができます。
Comparing Strings
文字列の比較
Swift provides three ways to compare textual values: string and character equality, prefix equality, and suffix equality.
Swift は、テキスト値を比較する 3 つの方法、つまり文字列と文字の同等性、接頭辞の同等性、および接尾辞の同等性を提供します。
String and Character Equality
文字列と文字の等価性
String and character equality is checked with the “equal to” operator (==) and the “not equal to” operator (!=), as described in Comparison Operators:
文字列と文字の等しいかどうかは、「比較演算子」で説明されているように、「等しい」演算子 (==) と「等しくない」演算子 (!=) でチェックされます。
let quotation = "We're a lot alike, you and I."
let sameQuotation = "We're a lot alike, you and I."
if quotation == sameQuotation {
print("These two strings are considered equal")
}
// Prints "These two strings are considered equal"
Two String values (or two Character values) are considered equal if their extended grapheme clusters are canonically equivalent. Extended grapheme clusters are canonically equivalent if they have the same linguistic meaning and appearance, even if they’re composed from different Unicode scalars behind the scenes.
2 つのString値(または 2 つのCharacter値)は、それらの拡張書記素クラスタが標準的に同等である場合、等しいとみなされます。 拡張書記素クラスターは、たとえバックグラウンドで異なる Unicode スカラーから構成されていたとしても、言語的な意味と外観が同じであれば、正規的に同等です。
For example, LATIN SMALL LETTER E WITH ACUTE (U+00E9) is canonically equivalent to LATIN SMALL LETTER E (U+0065) followed by COMBINING ACUTE ACCENT (U+0301). Both of these extended grapheme clusters are valid ways to represent the character é, and so they’re considered to be canonically equivalent:
たとえば、ラテン小文字 E WITH ACUTE (U+00E9) は、標準的には、ラテン小文字 E (U+0065) の後にアキュート アクセントを組み合わせたもの (U+0301) と同等です。 これらの拡張書記素クラスターは両方とも、文字 é を表現する有効な方法であるため、標準的に同等であるとみなされます。
// "Voulez-vous un café?" using LATIN SMALL LETTER E WITH ACUTE
let eAcuteQuestion = "Voulez-vous un caf\u{E9}?"
// "Voulez-vous un café?" using LATIN SMALL LETTER E and COMBINING ACUTE ACCENT
let combinedEAcuteQuestion = "Voulez-vous un caf\u{65}\u{301}?"
if eAcuteQuestion == combinedEAcuteQuestion {
print("These two strings are considered equal")
}
// Prints "These two strings are considered equal"
Conversely, LATIN CAPITAL LETTER A (U+0041, or "A"), as used in English, is not equivalent to CYRILLIC CAPITAL LETTER A (U+0410, or "А"), as used in Russian. The characters are visually similar, but don’t have the same linguistic meaning:
逆に、英語で使用されるラテン大文字 A (U+0041、または「A」) は、ロシア語で使用されるキリル大文字 A (U+0410、または「А」) と同等ではありません。 これらの文字は視覚的には似ていますが、言語的な意味は同じではありません。
let latinCapitalLetterA: Character = "\u{41}"
let cyrillicCapitalLetterA: Character = "\u{0410}"
if latinCapitalLetterA != cyrillicCapitalLetterA {
print("These two characters aren't equivalent.")
}
// Prints "These two characters aren't equivalent."
Note
注釈
String and character comparisons in Swift aren’t locale-sensitive.
Swift の文字列と文字の比較はロケールに依存しません。
Prefix and Suffix Equality
接頭語と接尾語の等価性
To check whether a string has a particular string prefix or suffix, call the string’s hasPrefix(_:) and hasSuffix(_:) methods, both of which take a single argument of type String and return a Boolean value.
文字列に特定の文字列接頭語または接尾語があるかどうかを確認するには、文字列の hasPrefix(:) メソッドと hasSuffix(:) メソッドを呼び出します。どちらも String 型の単一の引数を受け取り、ブール値を返します。
The examples below consider an array of strings representing the scene locations from the first two acts of Shakespeare’s Romeo and Juliet:
以下の例では、シェイクスピアの「ロミオとジュリエット」の最初の 2 幕のシーンの場所を表す文字列の配列を検討します。
let romeoAndJuliet = [
"Act 1 Scene 1: Verona, A public place",
"Act 1 Scene 2: Capulet's mansion",
"Act 1 Scene 3: A room in Capulet's mansion",
"Act 1 Scene 4: A street outside Capulet's mansion",
"Act 1 Scene 5: The Great Hall in Capulet's mansion",
"Act 2 Scene 1: Outside Capulet's mansion",
"Act 2 Scene 2: Capulet's orchard",
"Act 2 Scene 3: Outside Friar Lawrence's cell",
"Act 2 Scene 4: A street in Verona",
"Act 2 Scene 5: Capulet's mansion",
"Act 2 Scene 6: Friar Lawrence's cell"
]
You can use the hasPrefix(_:) method with the romeoAndJuliet array to count the number of scenes in Act 1 of the play:
hasPrefix(_:) メソッドを romeoAndJuliet 配列で使用すると、演劇の第 1 幕のシーンの数をカウントできます。
var act1SceneCount = 0
for scene in romeoAndJuliet {
if scene.hasPrefix("Act 1 ") {
act1SceneCount += 1
}
}
print("There are \(act1SceneCount) scenes in Act 1")
// Prints "There are 5 scenes in Act 1"
Similarly, use the hasSuffix(_:) method to count the number of scenes that take place in or around Capulet’s mansion and Friar Lawrence’s cell:
同様に、hasSuffix(_:) メソッドを使用して、キャピュレット邸とローレンス修道士の独房内またはその周辺で起こるシーンの数を数えます。
var mansionCount = 0
var cellCount = 0
for scene in romeoAndJuliet {
if scene.hasSuffix("Capulet's mansion") {
mansionCount += 1
} else if scene.hasSuffix("Friar Lawrence's cell") {
cellCount += 1
}
}
print("\(mansionCount) mansion scenes; \(cellCount) cell scenes")
// Prints "6 mansion scenes; 2 cell scenes"
Note
注釈
The hasPrefix(_:) and hasSuffix(_:) methods perform a character-by-character canonical equivalence comparison between the extended grapheme clusters in each string, as described in String and Character Equality.
hasPrefix(:) メソッドと hasSuffix(:) メソッドは、「文字列と文字の等価性」で説明されているように、各文字列内の拡張書記素クラスター間の正規等価比較を文字ごとに実行します。
Unicode Representations of Strings
文字列の Unicode 表現
When a Unicode string is written to a text file or some other storage, the Unicode scalars in that string are encoded in one of several Unicode-defined encoding forms. Each form encodes the string in small chunks known as code units. These include the UTF-8 encoding form (which encodes a string as 8-bit code units), the UTF-16 encoding form (which encodes a string as 16-bit code units), and the UTF-32 encoding form (which encodes a string as 32-bit code units).
Unicode 文字列がテキスト ファイルまたはその他のストレージに書き込まれると、その文字列内の Unicode スカラーは、Unicode で定義されたいくつかのエンコード形式のいずれかでエンコードされます。 各形式は、コード単位と呼ばれる小さな塊で文字列をエンコードします。 これらには、UTF-8 エンコード形式 (文字列を 8 ビット コード単位としてエンコードする)、UTF-16 エンコード形式 (文字列を 16 ビット コード単位としてエンコードする)、および UTF-32 エンコード形式 (文字列を 8 ビット コード単位としてエンコードする) が含まれます。 32 ビット コード単位としての文字列)。
Swift provides several different ways to access Unicode representations of strings. You can iterate over the string with a for–in statement, to access its individual Character values as Unicode extended grapheme clusters. This process is described in Working with Characters.
Swift は、文字列の Unicode 表現にアクセスするためのいくつかの異なる方法を提供します。 for-in ステートメントを使用して文字列を反復処理し、Unicode 拡張書記素クラスターとして個々の Character 値にアクセスできます。 このプロセスについては、「キャラクターの操作」で説明されています。
Alternatively, access a String value in one of three other Unicode-compliant representations:
あるいは、他の 3 つの Unicode 準拠表現のいずれかで String 値にアクセスします。
- A collection of UTF-8 code units (accessed with the string’s
utf8property) - UTF-8 コード単位のコレクション(文字列の
utf8プロパティでアクセス) - A collection of UTF-16 code units (accessed with the string’s
utf16property) - UTF-16 コード単位のコレクション(文字列の
utf16プロパティでアクセス) - A collection of 21-bit Unicode scalar values, equivalent to the string’s UTF-32 encoding form (accessed with the string’s
unicodeScalarsproperty) - 文字列の UTF-32 エンコード形式に相当する 21 ビット Unicode スカラー値のコレクション(文字列の
unicodeScalarsプロパティでアクセス)
Each example below shows a different representation of the following string, which is made up of the characters D, o, g, ‼ (DOUBLE EXCLAMATION MARK, or Unicode scalar U+203C), and the 🐶 character (DOG FACE, or Unicode scalar U+1F436):
以下の各例は、文字 D, o, g, ‼ DOUBLE EXCLAMATION MARK、または Unicode スカラー U+203C) と 🐶 文字 (DOG FACE、または Unicode スカラーU+1F436) で構成される文字列のさまざまな表現を示しています。:
let dogString = "Dog‼🐶"
UTF-8 Representation
UTF-8 表現
You can access a UTF-8 representation of a String by iterating over its utf8 property. This property is of type String.UTF8View, which is a collection of unsigned 8-bit (UInt8) values, one for each byte in the string’s UTF-8 representation:
utf8 プロパティを反復処理することで、Stringの UTF-8表現にアクセスできます。 このプロパティは String.UTF8View 型で、符号なし 8 ビット (UInt8) 値のコレクションであり、文字列の UTF-8 表現の各バイトに 1 つずつ含まれます。

for codeUnit in dogString.utf8 {
print("\(codeUnit) ", terminator: "")
}
print("")
// Prints "68 111 103 226 128 188 240 159 144 182 "
In the example above, the first three decimal codeUnit values (68, 111, 103) represent the characters D, o, and g, whose UTF-8 representation is the same as their ASCII representation. The next three decimal codeUnit values (226, 128, 188) are a three-byte UTF-8 representation of the DOUBLE EXCLAMATION MARK character. The last four codeUnit values (240, 159, 144, 182) are a four-byte UTF-8 representation of the DOG FACE character.
上の例では、最初の 3 つの 10 進数 codeUnit 値(68、111、103)は文字 D、o、g を表しており、その UTF-8 表現は ASCII 表現と同じです。 次の 3 つの 10 進数 codeUnit 値(226、128、188)は、二重感嘆符文字の 3 バイトの UTF-8 表現です。 最後の 4 つの codeUnit 値(240、159、144、182)は、DOG FACE 文字の 4 バイト UTF-8 表現です。
UTF-16 Representation
UTF-16 表現
You can access a UTF-16 representation of a String by iterating over its utf16 property. This property is of type String.UTF16View, which is a collection of unsigned 16-bit (UInt16) values, one for each 16-bit code unit in the string’s UTF-16 representation:
utf16 プロパティを反復処理することで、Stringの UTF-16 表現にアクセスできます。 このプロパティは String.UTF16View 型で、符号なし 16 ビット (UInt16) 値のコレクションであり、文字列の UTF-16 表現の 16 ビット コード単位ごとに 1 つずつあります。

for codeUnit in dogString.utf16 {
print("\(codeUnit) ", terminator: "")
}
print("")
// Prints "68 111 103 8252 55357 56374 "
Again, the first three codeUnit values (68, 111, 103) represent the characters D, o, and g, whose UTF-16 code units have the same values as in the string’s UTF-8 representation (because these Unicode scalars represent ASCII characters).
繰り返しますが、最初の 3 つの codeUnit 値(68、111、103)は文字 D、o、g を表し、その UTF-16 コード単位は文字列の UTF-8 表現と同じ値を持ちます(これらの Unicode スカラーは ASCII 文字を表すため) 。
The fourth codeUnit value (8252) is a decimal equivalent of the hexadecimal value 203C, which represents the Unicode scalar U+203C for the DOUBLE EXCLAMATION MARK character. This character can be represented as a single code unit in UTF-16.
4 番目の codeUnit 値 (8252) は、16 進値 203C に相当する 10 進数で、二重感嘆符文字の Unicode スカラー U+203C を表します。 この文字は、UTF-16 では単一のコード単位として表現できます。
The fifth and sixth codeUnit values (55357 and 56374) are a UTF-16 surrogate pair representation of the DOG FACE character. These values are a high-surrogate value of U+D83D (decimal value 55357) and a low-surrogate value of U+DC36 (decimal value 56374).
5 番目と 6 番目の codeUnit 値(55357 と 56374)は、DOG FACE キャラクターの UTF-16 サロゲート ペア表現です。 これらの値は、上位サロゲート値 U+D83D (10 進数 55357) と下位サロゲート値 U+DC36 (10 進数 56374) です。
Unicode Scalar Representation
Unicode スカラー表現
You can access a Unicode scalar representation of a String value by iterating over its unicodeScalars property. This property is of type UnicodeScalarView, which is a collection of values of type UnicodeScalar.
String 値の Unicode スカラー表現にアクセスするには、その unicodeScalars プロパティを反復処理します。 このプロパティは UnicodeScalarView タイプであり、UnicodeScalar タイプの値のコレクションです。
Each UnicodeScalar has a value property that returns the scalar’s 21-bit value, represented within a UInt32 value:
各 UnicodeScalar には、UInt32 値内で表されるスカラーの 21 ビット値を返す value プロパティがあります。

for scalar in dogString.unicodeScalars {
print("\(scalar.value) ", terminator: "")
}
print("")
// Prints "68 111 103 8252 128054 "
The value properties for the first three UnicodeScalar values (68, 111, 103) once again represent the characters D, o, and g.
最初の 3 つの UnicodeScalar 値(68、111、103)のvalueプロパティも、文字 D、o、g を表します。
The fourth codeUnit value (8252) is again a decimal equivalent of the hexadecimal value 203C, which represents the Unicode scalar U+203C for the DOUBLE EXCLAMATION MARK character.
4 番目の codeUnit 値 (8252) も、16 進値 203C に相当する 10 進数で、二重感嘆符文字の Unicode スカラー U+203C を表します。
The value property of the fifth and final UnicodeScalar, 128054, is a decimal equivalent of the hexadecimal value 1F436, which represents the Unicode scalar U+1F436 for the DOG FACE character.
5 番目で最後の UnicodeScalar のvalueプロパティ 128054 は、DOG FACE 文字の Unicode スカラー U+1F436 を表す 16 進値 1F436 に相当する 10 進数です。
As an alternative to querying their value properties, each UnicodeScalar value can also be used to construct a new String value, such as with string interpolation:
valueのプロパティをクエリする代わりに、各 UnicodeScalar 値を使用して、文字列補間などの新しい String 値を構築することもできます。
for scalar in dogString.unicodeScalars {
print("\(scalar) ")
}
// D
// o
// g
// ‼
// 🐶
Beta Software
ベータソフトウェアー
This documentation contains preliminary information about an API or technology in development. This information is subject to change, and software implemented according to this documentation should be tested with final operating system software.
このドキュメントには、開発中の API またはテクノロジに関する予備情報が含まれています。 この情報は変更される可能性があり、このドキュメントに従って実装されたソフトウェアは、最終的なオペレーティング システム ソフトウェアでテストする必要があります。
Learn more about using Apple’s beta software(Link:developer.apple.com).
詳しくはApple’s beta software(Link:developer.apple.com)(英語)の使用についてをご覧ください。